Hockey Analytics
Platform

Six phases.
Five delivered.
The data existed.
The story didn't.
Most data engineering portfolio projects generate random data, build a pipeline on top of it, and stop there. The output is technically correct but tells no story a business person would recognize.
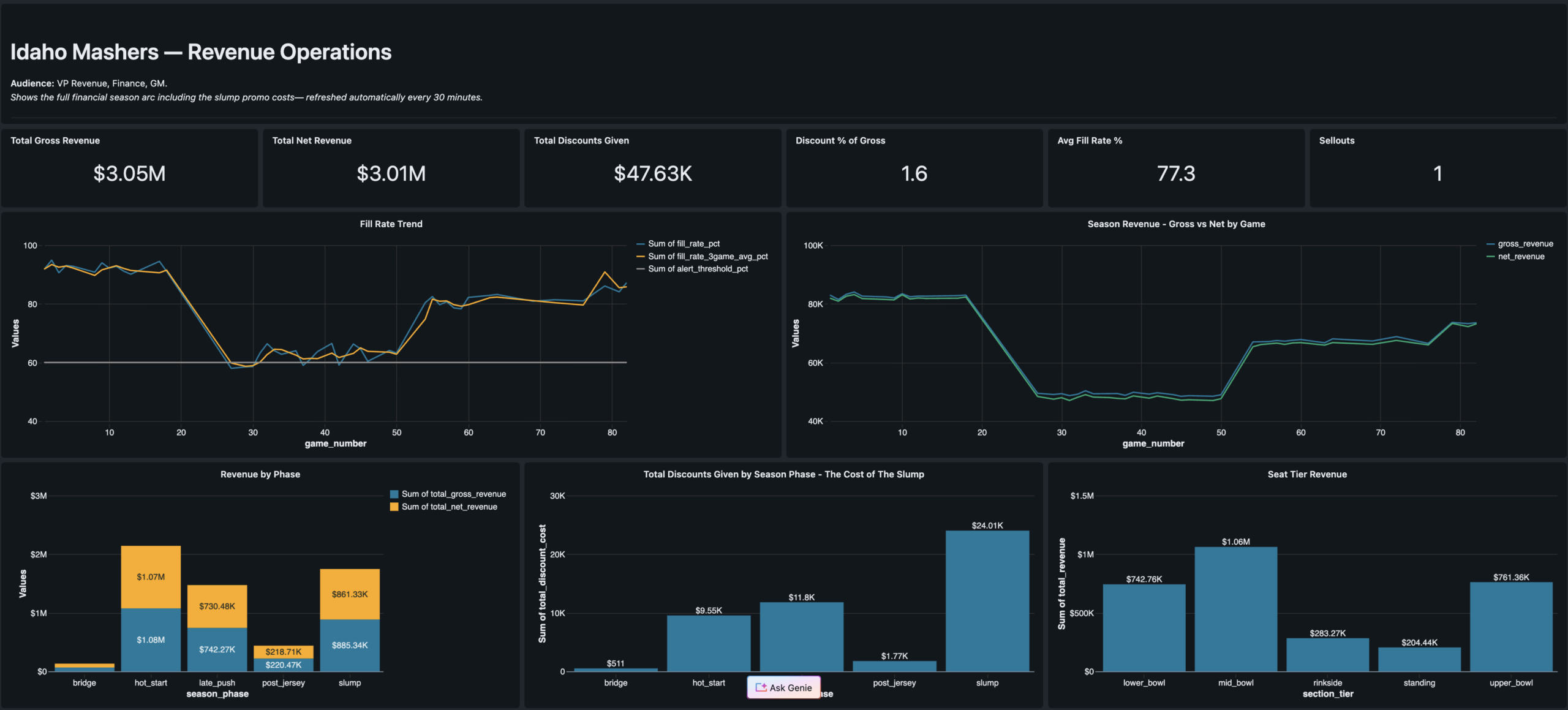
IceBase was designed differently. Every number in this platform was deliberately authored to reflect real business situations that sports organizations actually face — a hot start, a midseason slump where marketing over-relied on discounts, a late-season comeback, and a jersey retirement ceremony that became the single biggest fan acquisition event of the year.
The goal was to build a platform where every spike and drop in the data has a cause you can explain to a CMO, a VP of Revenue, or a retention manager. The pipeline, the ML models, and the dashboards were all built to surface both the good stories and the bad ones.
The season arc — hot start, midseason slump, late push, Jersey Night — is encoded as a Python configuration object in the seed generator. Every downstream table, model, and dashboard inherits this narrative. That's what makes it a business intelligence project, not just a data engineering exercise.
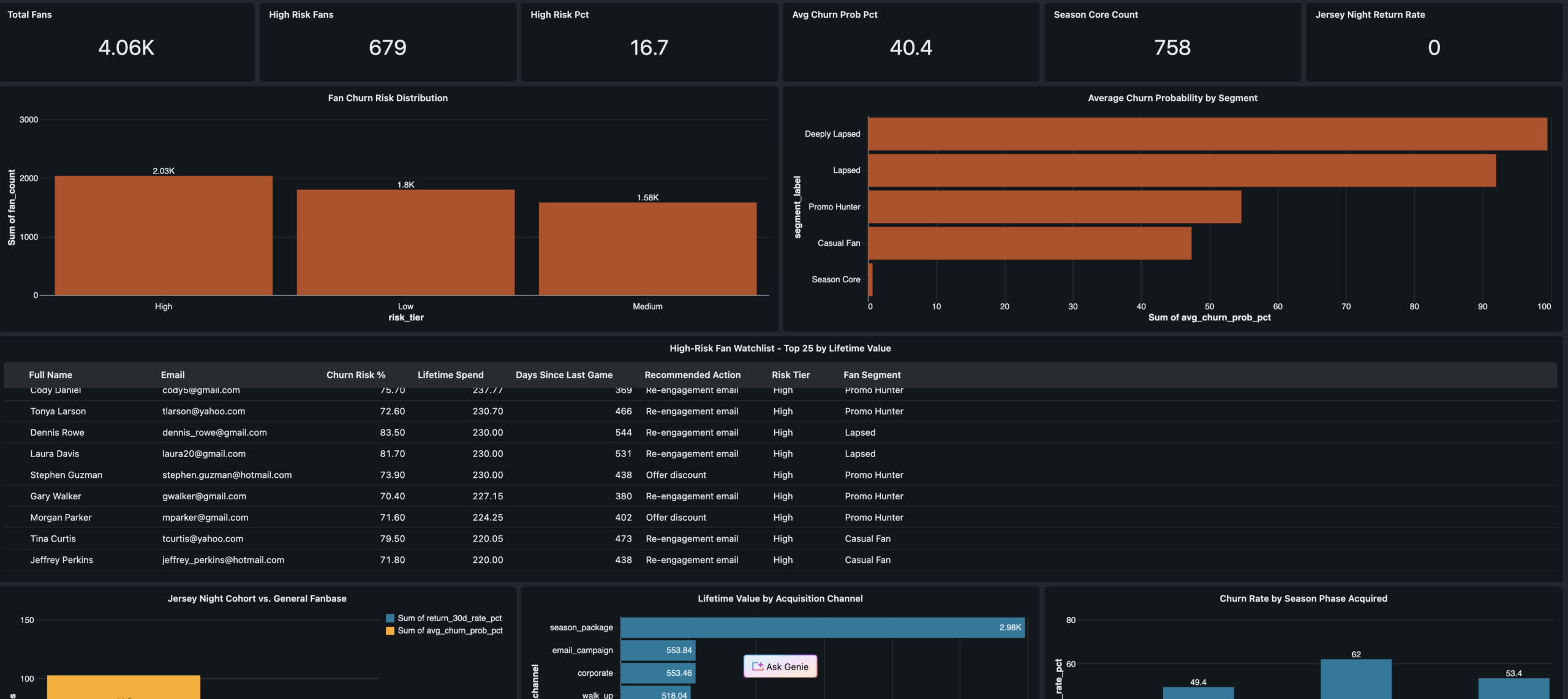
- Season Core fans showed near-zero churn through the slump — proving loyalty program ROI
- Jersey Night reactivated 94 deeply lapsed fans and drove a 31% 30-day return rate
- XGBoost model flagged 600+ at-risk fans before full churn — with a real intervention window
- 412 net-new fans acquired on Jersey Night — highest single-event acquisition of the season
- Promo over-reliance during the slump grew the Promo Hunter segment from 8% to 22% of the fan base
- 67% of walk-up buyers from the hot start never attended another game — vanity acquisition metrics
- Marketing had no follow-up playbook for the 412 Jersey Night new acquisitions — 61% received zero outreach
- Data leakage caught in XGBoost training — AUC of 1.0 diagnosed and fixed to a real 0.94
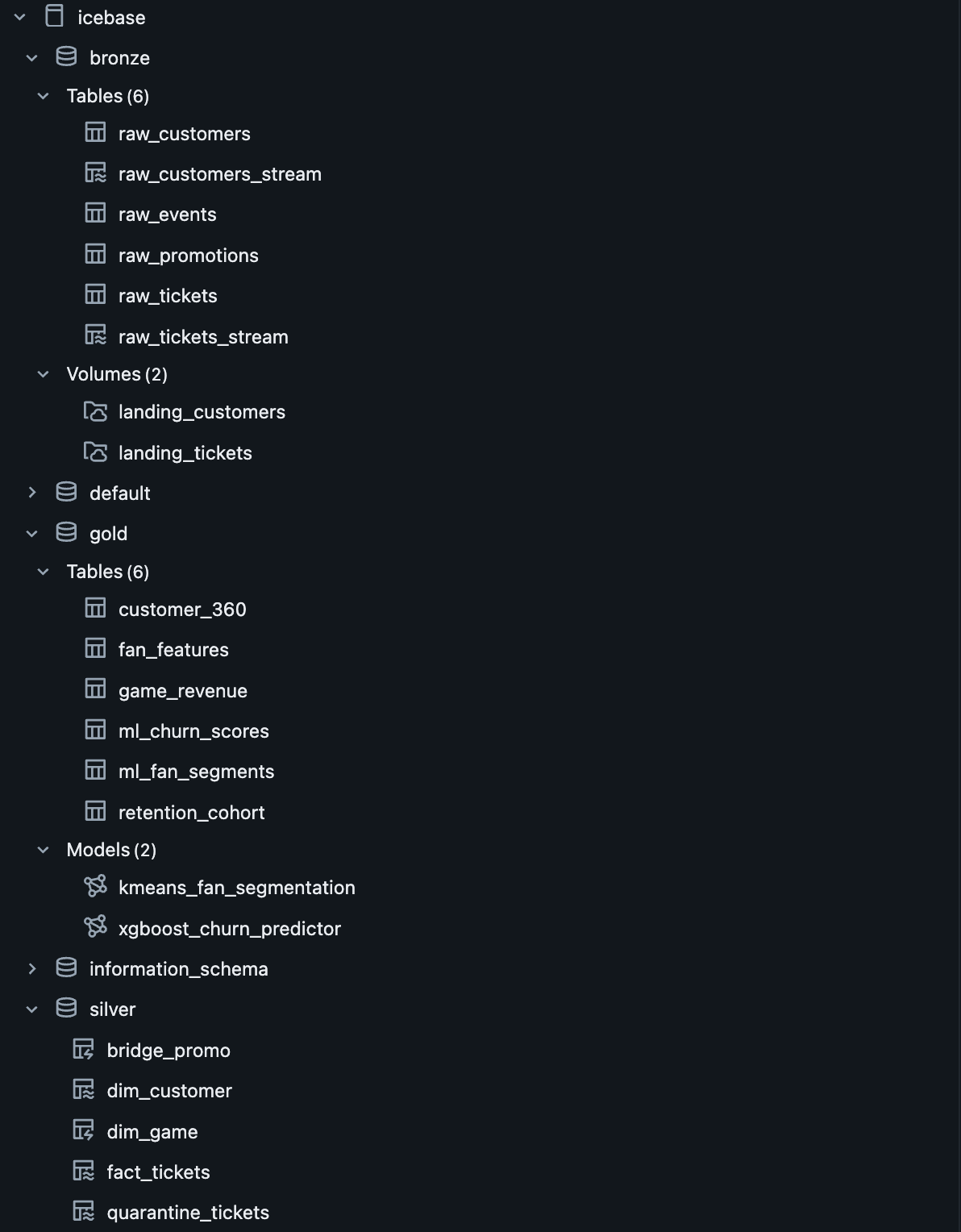
Medallion architecture
end to end.
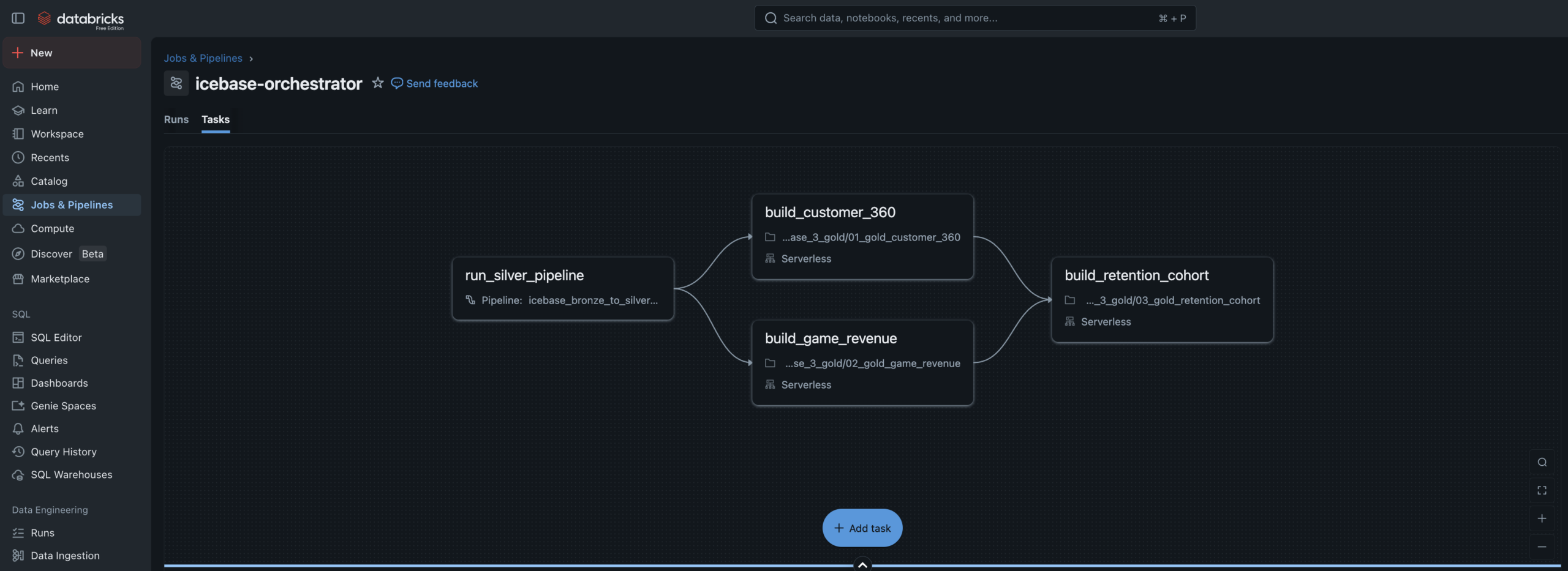
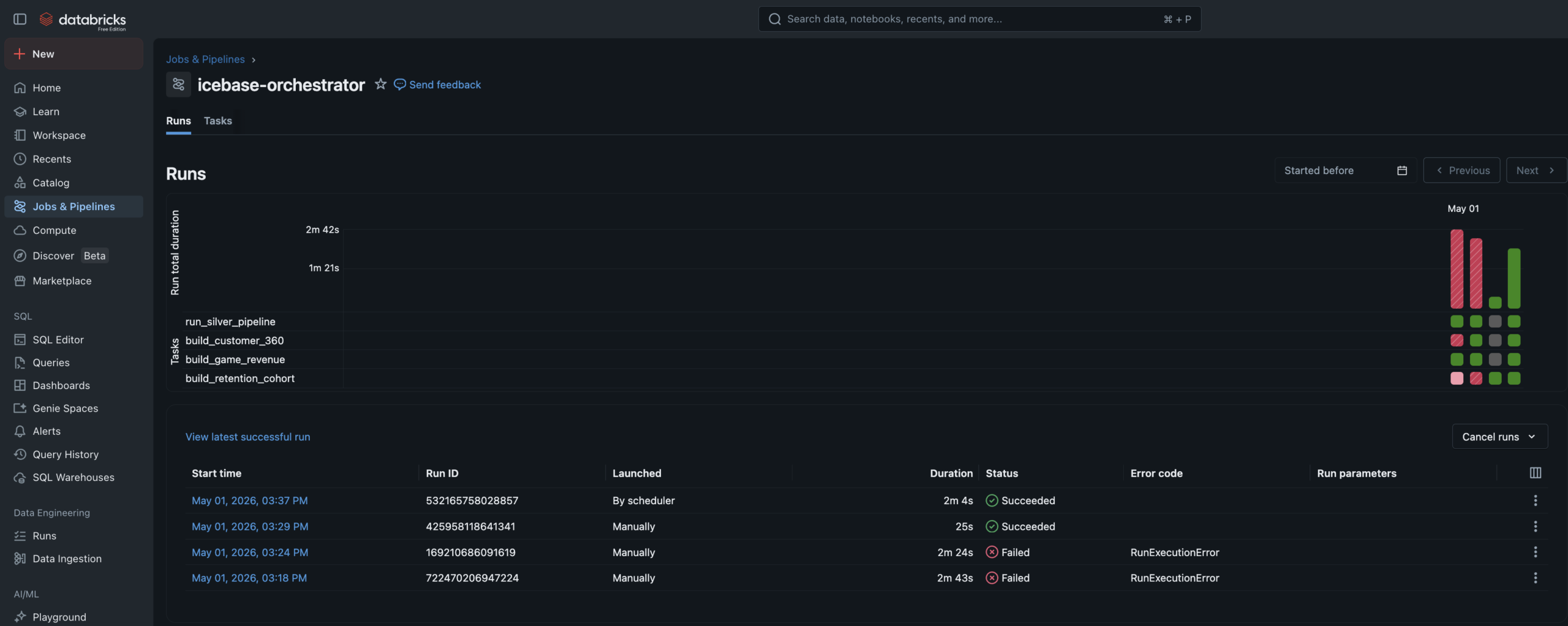
Unity Catalog governs every layer. Lakeflow handles Bronze→Silver declaratively. Gold is orchestrated by a multi-task Job DAG. ML models live in the Unity Catalog Model Registry with full feature lineage.
Seed Generator
Simulator
Landing Zone
_stream
_stream
raw_promotions
fact_tickets
bridge_promo
_tickets
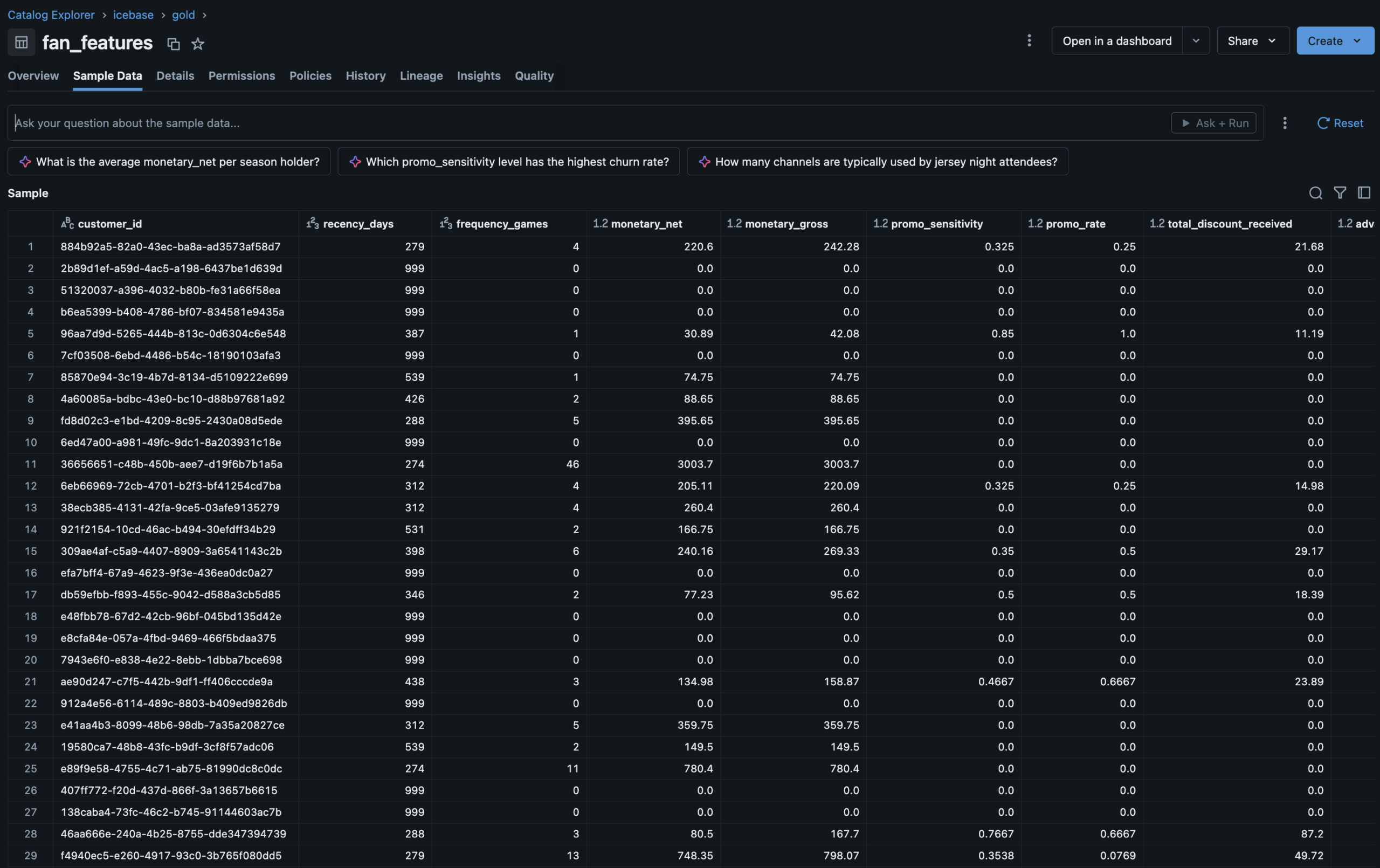
fan_features
retention_cohort
ml_churn_scores
Segmentation
Churn Model
UC Registry
Dashboard
Dashboard
Explorer
Declarative Bronze
to Silver.
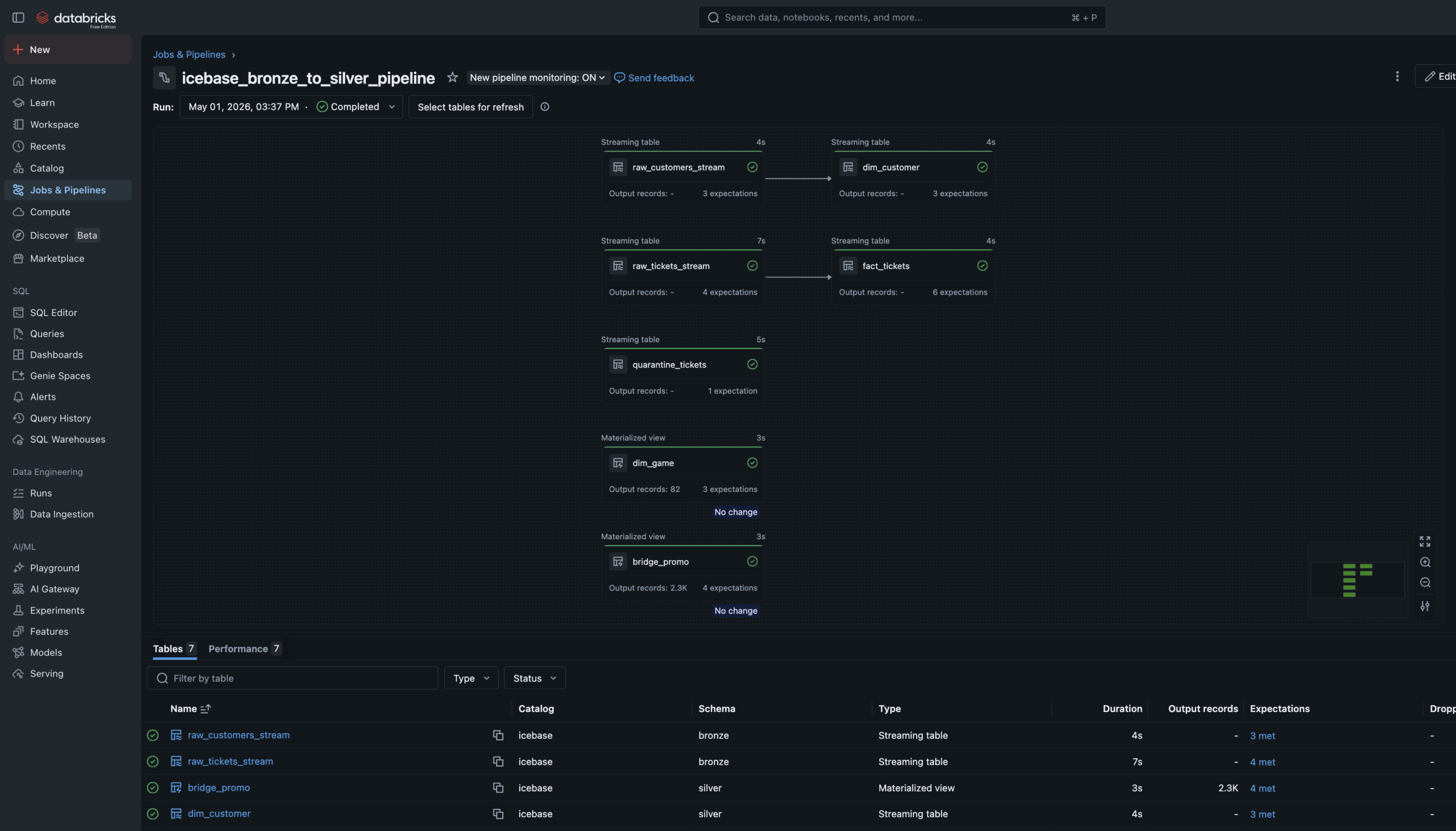
The Bronze→Silver pipeline is a Lakeflow Spark Declarative Pipeline — six notebooks registered as pipeline source files. The language split is intentional: SQL for single-source streaming tables and materialized views, Python for tables that need to union two independent readStreams.
Auto Loader watches the Unity Catalog Volume landing zones and ingests new JSON files incrementally — only processing files not yet seen. Schema evolution is handled automatically. Checkpoint management is owned by the pipeline runtime.
Data Quality Expectations are enforced at Silver. Null IDs and invalid prices are hard-dropped via expect_or_drop. Bad records don't disappear silently — they route to a quarantine_tickets table for investigation.
Three Gold tables.
One automated Job.
Two models.
Full lineage.
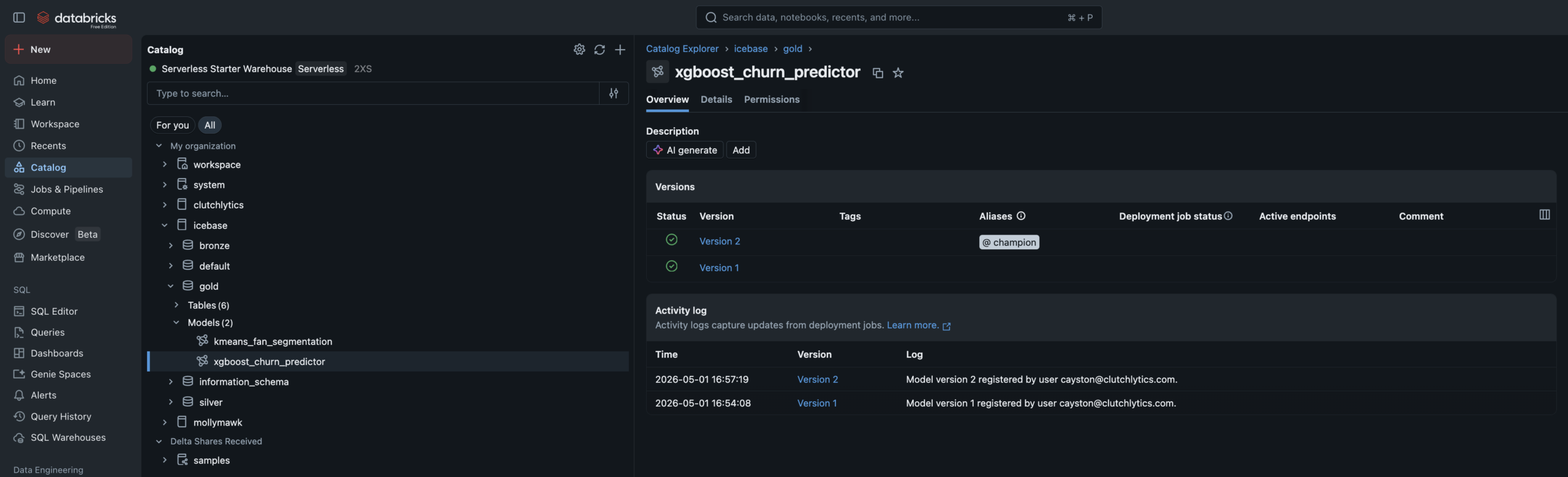
Both models read from a Unity Catalog Feature Table, tracked in MLflow with full experiment logging, and registered in the Unity Catalog Model Registry. Predictions write back to Gold as enrichment tables.
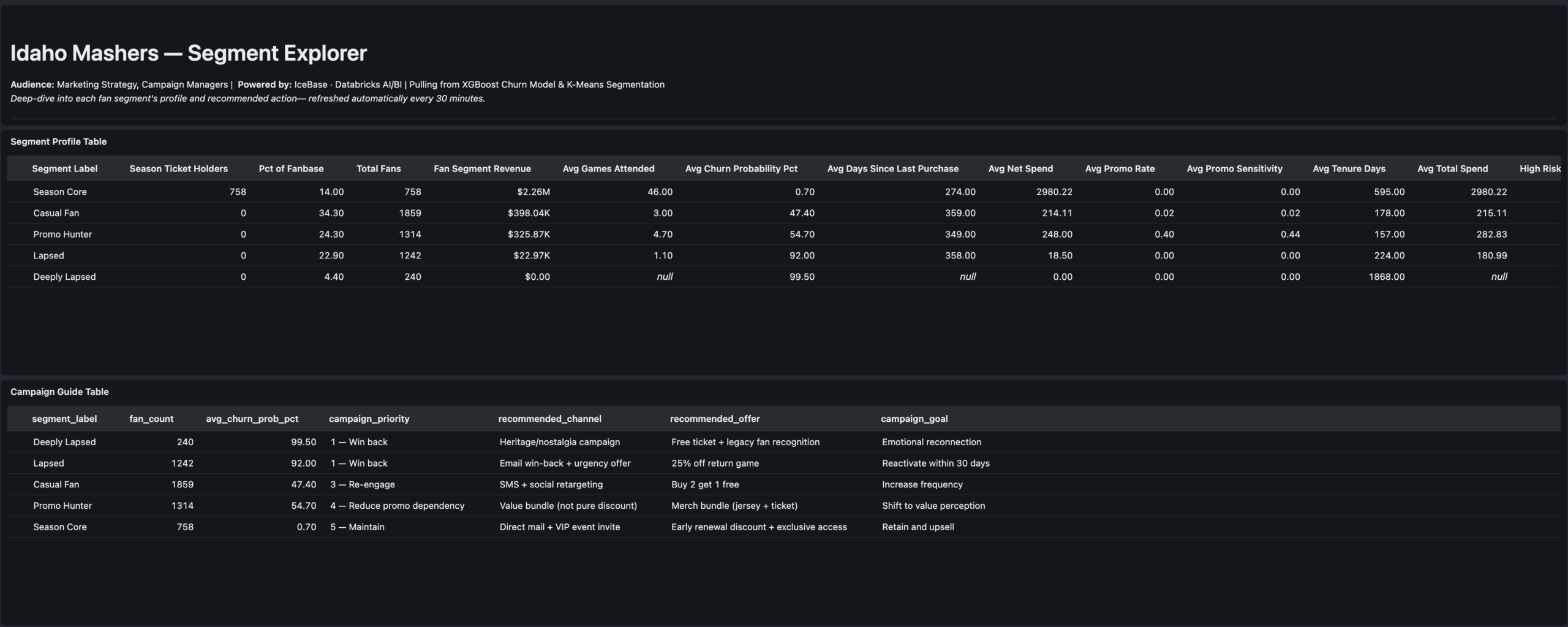
- Features: RFM metrics, promo sensitivity, seat tier rank, tenure, purchase timing
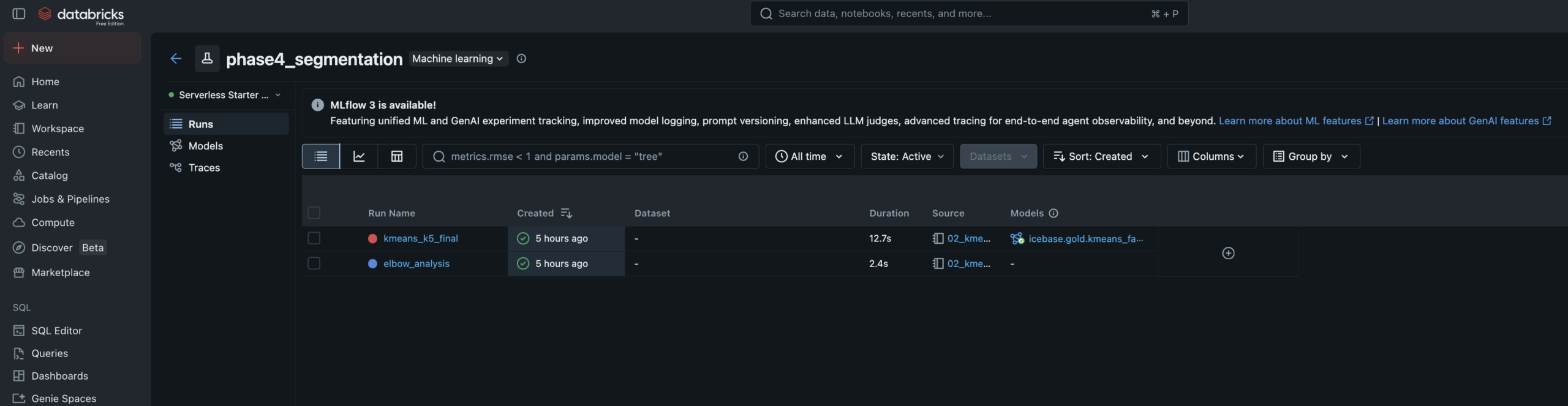
- Elbow analysis run for k=2–8, logged to MLflow — k=5 selected at inflection point
- Cluster labels assigned manually by reading centroid profiles — practitioner judgment step
- Segments: Season Core · Casual Fan · Promo Hunter · Lapsed · Deeply Lapsed
- Writes
icebase.gold.ml_fan_segmentsback to Unity Catalog
- Algorithm: XGBoost binary classifier — churn defined as no purchase in 45+ days
- Training data: Built via FeatureEngineeringClient for full feature lineage tracking
- Data leakage caught and fixed — AUC of 1.0 diagnosed (recency_days leakage), resolved to 0.94
- Champion alias set in UC Model Registry — promoting new versions requires no code changes
- Writes
ml_churn_scoreswith High/Medium/Low risk tiers
Three dashboards.
One team, one brand.
Three AI/BI dashboards built on Databricks SQL — each one answering a specific executive's questions. Branded with the Idaho Mashers identity. All powered live from Gold and ML output tables.

The stat sheet
Key decisions &
tradeoffs
The choices that shaped the architecture — and what was knowingly accepted or given up at each step.
| Decision | Rationale | Tradeoff |
|---|---|---|
| Authored narrative over random data | Random seed data produces technically correct pipelines but tells no business story. The PHASE_WEIGHTS configuration object encodes fill rate, price multiplier, promo rate, and acquisition volume for each game range — making every downstream number explainable to a CMO, not just a data engineer. | More build time upfront — designing the narrative before generating a single row added significant design work. Paid for itself in the quality of the ML validation and dashboard storytelling. |
| 6-notebook pipeline with language split | Lakeflow pipeline source files must be single-language — SQL or Python, not both. The split is intentional: SQL for single-source tables and materialized views (cleaner, more readable), Python where two independent readStreams need to be unioned — which SQL cannot express cleanly. | Correct implementation — attempting mixed-language notebooks was the first approach and failed. The 6-notebook solution reflects how Databricks Lakeflow actually works, not how older DLT documentation implied it worked. |
| Quarantine table over silent drops | Most pipeline tutorials drop bad records and move on. Routing them to a named quarantine table means bad data is preserved for investigation, the pipeline event log shows exactly how many records failed each expectation, and a SQL Alert can fire when the count spikes. | Production pattern — adds one more streaming table to manage, but the observability gain is significant. This is the pattern a senior data engineer would reach for in a real org. |
| Remove recency_days from churn model | Initial XGBoost training produced AUC of 1.0 — the signal that something was wrong. recency_days is mathematically derived from churn_flag (no purchase in 45+ days). Leaving it in the model means the model learns a tautology, not fan behavior. Removing it produced a real 0.94 AUC. | Honest model — 0.94 AUC on clean behavioral features is a genuinely strong result. The leakage catch and fix is a stronger portfolio signal than a perfect 1.0 would have been. |
| Champion alias over versioned model staging | Unity Catalog replaced the old Staging/Production stage model with named aliases. Setting a "champion" alias on the registered model means downstream scoring notebooks reference @champion — not a version number. Promoting a retrained model requires updating the alias pointer, not changing any code. |
Alias documentation required — anyone unfamiliar with the UC alias pattern needs context. Accepted in exchange for a promotion workflow that doesn't require code changes in scoring notebooks. |
| Three dashboards over one unified report | The CMO, VP Revenue, and Marketing Strategy leads ask fundamentally different questions. A unified dashboard forces cognitive filtering that reduces adoption. One persona per dashboard is a product decision — each dashboard is structured around exactly one executive's mental model of the data. | More build and maintenance surface — three dashboards to update when the Gold schema evolves. Accepted as the correct product tradeoff for usability and stakeholder clarity. |
Screenshot gallery
Every pipeline artifact, ML experiment, and dashboard view from the live Databricks workspace.